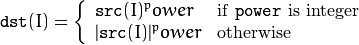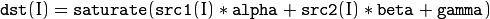Per-element Operations
cuda::add
Computes a matrix-matrix or matrix-scalar sum.
-
C++: void cuda::add(InputArray src1, InputArray src2, OutputArray dst, InputArray mask=noArray(), int dtype=-1, Stream& stream=Stream::Null())
| Parameters: |
- src1 – First source matrix or scalar.
- src2 – Second source matrix or scalar. Matrix should have the same size and type as src1 .
- dst – Destination matrix that has the same size and number of channels as the input array(s). The depth is defined by dtype or src1 depth.
- mask – Optional operation mask, 8-bit single channel array, that specifies elements of the destination array to be changed.
- dtype – Optional depth of the output array.
- stream – Stream for the asynchronous version.
|
|---|
cuda::subtract
Computes a matrix-matrix or matrix-scalar difference.
-
C++: void cuda::subtract(InputArray src1, InputArray src2, OutputArray dst, InputArray mask=noArray(), int dtype=-1, Stream& stream=Stream::Null())
| Parameters: |
- src1 – First source matrix or scalar.
- src2 – Second source matrix or scalar. Matrix should have the same size and type as src1 .
- dst – Destination matrix that has the same size and number of channels as the input array(s). The depth is defined by dtype or src1 depth.
- mask – Optional operation mask, 8-bit single channel array, that specifies elements of the destination array to be changed.
- dtype – Optional depth of the output array.
- stream – Stream for the asynchronous version.
|
|---|
cuda::multiply
Computes a matrix-matrix or matrix-scalar per-element product.
-
C++: void cuda::multiply(InputArray src1, InputArray src2, OutputArray dst, double scale=1, int dtype=-1, Stream& stream=Stream::Null())
| Parameters: |
- src1 – First source matrix or scalar.
- src2 – Second source matrix or scalar.
- dst – Destination matrix that has the same size and number of channels as the input array(s). The depth is defined by dtype or src1 depth.
- scale – Optional scale factor.
- dtype – Optional depth of the output array.
- stream – Stream for the asynchronous version.
|
|---|
cuda::divide
Computes a matrix-matrix or matrix-scalar division.
-
C++: void cuda::divide(InputArray src1, InputArray src2, OutputArray dst, double scale=1, int dtype=-1, Stream& stream=Stream::Null())
-
C++: void cuda::divide(double src1, InputArray src2, OutputArray dst, int dtype=-1, Stream& stream=Stream::Null())
| Parameters: |
- src1 – First source matrix or a scalar.
- src2 – Second source matrix or scalar.
- dst – Destination matrix that has the same size and number of channels as the input array(s). The depth is defined by dtype or src1 depth.
- scale – Optional scale factor.
- dtype – Optional depth of the output array.
- stream – Stream for the asynchronous version.
|
|---|
This function, in contrast to divide(), uses a round-down rounding mode.
cuda::absdiff
Computes per-element absolute difference of two matrices (or of a matrix and scalar).
-
C++: void cuda::absdiff(InputArray src1, InputArray src2, OutputArray dst, Stream& stream=Stream::Null())
| Parameters: |
- src1 – First source matrix or scalar.
- src2 – Second source matrix or scalar.
- dst – Destination matrix that has the same size and type as the input array(s).
- stream – Stream for the asynchronous version.
|
|---|
cuda::abs
Computes an absolute value of each matrix element.
-
C++: void cuda::abs(InputArray src, OutputArray dst, Stream& stream=Stream::Null())
| Parameters: |
- src – Source matrix.
- dst – Destination matrix with the same size and type as src .
- stream – Stream for the asynchronous version.
|
|---|
cuda::sqr
Computes a square value of each matrix element.
-
C++: void cuda::sqr(InputArray src, OutputArray dst, Stream& stream=Stream::Null())
| Parameters: |
- src – Source matrix.
- dst – Destination matrix with the same size and type as src .
- stream – Stream for the asynchronous version.
|
|---|
cuda::sqrt
Computes a square root of each matrix element.
-
C++: void cuda::sqrt(InputArray src, OutputArray dst, Stream& stream=Stream::Null())
| Parameters: |
- src – Source matrix.
- dst – Destination matrix with the same size and type as src .
- stream – Stream for the asynchronous version.
|
|---|
cuda::exp
Computes an exponent of each matrix element.
-
C++: void cuda::exp(InputArray src, OutputArray dst, Stream& stream=Stream::Null())
| Parameters: |
- src – Source matrix.
- dst – Destination matrix with the same size and type as src .
- stream – Stream for the asynchronous version.
|
|---|
cuda::log
Computes a natural logarithm of absolute value of each matrix element.
-
C++: void cuda::log(InputArray src, OutputArray dst, Stream& stream=Stream::Null())
| Parameters: |
- src – Source matrix.
- dst – Destination matrix with the same size and type as src .
- stream – Stream for the asynchronous version.
|
|---|
cuda::pow
Raises every matrix element to a power.
-
C++: void cuda::pow(InputArray src, double power, OutputArray dst, Stream& stream=Stream::Null())
| Parameters: |
- src – Source matrix.
- power – Exponent of power.
- dst – Destination matrix with the same size and type as src .
- stream – Stream for the asynchronous version.
|
|---|
The function pow raises every element of the input matrix to power :
cuda::compare
Compares elements of two matrices (or of a matrix and scalar).
-
C++: void cuda::compare(InputArray src1, InputArray src2, OutputArray dst, int cmpop, Stream& stream=Stream::Null())
-
cuda::bitwise_not
Performs a per-element bitwise inversion.
-
C++: void cuda::bitwise_not(InputArray src, OutputArray dst, InputArray mask=noArray(), Stream& stream=Stream::Null())
| Parameters: |
- src – Source matrix.
- dst – Destination matrix with the same size and type as src .
- mask – Optional operation mask. 8-bit single channel image.
- stream – Stream for the asynchronous version.
|
|---|
cuda::bitwise_or
Performs a per-element bitwise disjunction of two matrices (or of matrix and scalar).
-
C++: void cuda::bitwise_or(InputArray src1, InputArray src2, OutputArray dst, InputArray mask=noArray(), Stream& stream=Stream::Null())
| Parameters: |
- src1 – First source matrix or scalar.
- src2 – Second source matrix or scalar.
- dst – Destination matrix that has the same size and type as the input array(s).
- mask – Optional operation mask. 8-bit single channel image.
- stream – Stream for the asynchronous version.
|
|---|
cuda::bitwise_and
Performs a per-element bitwise conjunction of two matrices (or of matrix and scalar).
-
C++: void cuda::bitwise_and(InputArray src1, InputArray src2, OutputArray dst, InputArray mask=noArray(), Stream& stream=Stream::Null())
| Parameters: |
- src1 – First source matrix or scalar.
- src2 – Second source matrix or scalar.
- dst – Destination matrix that has the same size and type as the input array(s).
- mask – Optional operation mask. 8-bit single channel image.
- stream – Stream for the asynchronous version.
|
|---|
cuda::bitwise_xor
Performs a per-element bitwise exclusive or operation of two matrices (or of matrix and scalar).
-
C++: void cuda::bitwise_xor(InputArray src1, InputArray src2, OutputArray dst, InputArray mask=noArray(), Stream& stream=Stream::Null())
| Parameters: |
- src1 – First source matrix or scalar.
- src2 – Second source matrix or scalar.
- dst – Destination matrix that has the same size and type as the input array(s).
- mask – Optional operation mask. 8-bit single channel image.
- stream – Stream for the asynchronous version.
|
|---|
cuda::rshift
Performs pixel by pixel right shift of an image by a constant value.
-
C++: void cuda::rshift(InputArray src, Scalar_<int> val, OutputArray dst, Stream& stream=Stream::Null())
| Parameters: |
- src – Source matrix. Supports 1, 3 and 4 channels images with integers elements.
- val – Constant values, one per channel.
- dst – Destination matrix with the same size and type as src .
- stream – Stream for the asynchronous version.
|
|---|
cuda::lshift
Performs pixel by pixel right left of an image by a constant value.
-
C++: void cuda::lshift(InputArray src, Scalar_<int> val, OutputArray dst, Stream& stream=Stream::Null())
| Parameters: |
- src – Source matrix. Supports 1, 3 and 4 channels images with CV_8U , CV_16U or CV_32S depth.
- val – Constant values, one per channel.
- dst – Destination matrix with the same size and type as src .
- stream – Stream for the asynchronous version.
|
|---|
cuda::min
Computes the per-element minimum of two matrices (or a matrix and a scalar).
-
C++: void cuda::min(InputArray src1, InputArray src2, OutputArray dst, Stream& stream=Stream::Null())
| Parameters: |
- src1 – First source matrix or scalar.
- src2 – Second source matrix or scalar.
- dst – Destination matrix that has the same size and type as the input array(s).
- stream – Stream for the asynchronous version.
|
|---|
cuda::max
Computes the per-element maximum of two matrices (or a matrix and a scalar).
-
C++: void cuda::max(InputArray src1, InputArray src2, OutputArray dst, Stream& stream=Stream::Null())
| Parameters: |
- src1 – First source matrix or scalar.
- src2 – Second source matrix or scalar.
- dst – Destination matrix that has the same size and type as the input array(s).
- stream – Stream for the asynchronous version.
|
|---|
cuda::addWeighted
Computes the weighted sum of two arrays.
-
C++: void cuda::addWeighted(InputArray src1, double alpha, InputArray src2, double beta, double gamma, OutputArray dst, int dtype=-1, Stream& stream=Stream::Null())
| Parameters: |
- src1 – First source array.
- alpha – Weight for the first array elements.
- src2 – Second source array of the same size and channel number as src1 .
- beta – Weight for the second array elements.
- dst – Destination array that has the same size and number of channels as the input arrays.
- gamma – Scalar added to each sum.
- dtype – Optional depth of the destination array. When both input arrays have the same depth, dtype can be set to -1, which will be equivalent to src1.depth().
- stream – Stream for the asynchronous version.
|
|---|
The function addWeighted calculates the weighted sum of two arrays as follows:
where I is a multi-dimensional index of array elements. In case of multi-channel arrays, each channel is processed independently.
cuda::threshold
Applies a fixed-level threshold to each array element.
-
C++: double cuda::threshold(InputArray src, OutputArray dst, double thresh, double maxval, int type, Stream& stream=Stream::Null())
| Parameters: |
- src – Source array (single-channel).
- dst – Destination array with the same size and type as src .
- thresh – Threshold value.
- maxval – Maximum value to use with THRESH_BINARY and THRESH_BINARY_INV threshold types.
- type – Threshold type. For details, see threshold() . The THRESH_OTSU and THRESH_TRIANGLE threshold types are not supported.
- stream – Stream for the asynchronous version.
|
|---|
cuda::magnitude
Computes magnitudes of complex matrix elements.
-
C++: void cuda::magnitude(InputArray xy, OutputArray magnitude, Stream& stream=Stream::Null())
-
C++: void cuda::magnitude(InputArray x, InputArray y, OutputArray magnitude, Stream& stream=Stream::Null())
| Parameters: |
- xy – Source complex matrix in the interleaved format ( CV_32FC2 ).
- x – Source matrix containing real components ( CV_32FC1 ).
- y – Source matrix containing imaginary components ( CV_32FC1 ).
- magnitude – Destination matrix of float magnitudes ( CV_32FC1 ).
- stream – Stream for the asynchronous version.
|
|---|
cuda::magnitudeSqr
Computes squared magnitudes of complex matrix elements.
-
C++: void cuda::magnitudeSqr(InputArray xy, OutputArray magnitude, Stream& stream=Stream::Null() )
-
C++: void cuda::magnitudeSqr(InputArray x, InputArray y, OutputArray magnitude, Stream& stream=Stream::Null())
| Parameters: |
- xy – Source complex matrix in the interleaved format ( CV_32FC2 ).
- x – Source matrix containing real components ( CV_32FC1 ).
- y – Source matrix containing imaginary components ( CV_32FC1 ).
- magnitude – Destination matrix of float magnitude squares ( CV_32FC1 ).
- stream – Stream for the asynchronous version.
|
|---|
cuda::phase
Computes polar angles of complex matrix elements.
-
C++: void cuda::phase(InputArray x, InputArray y, OutputArray angle, bool angleInDegrees=false, Stream& stream=Stream::Null())
| Parameters: |
- x – Source matrix containing real components ( CV_32FC1 ).
- y – Source matrix containing imaginary components ( CV_32FC1 ).
- angle – Destination matrix of angles ( CV_32FC1 ).
- angleInDegrees – Flag for angles that must be evaluated in degrees.
- stream – Stream for the asynchronous version.
|
|---|
cuda::cartToPolar
Converts Cartesian coordinates into polar.
-
C++: void cuda::cartToPolar(InputArray x, InputArray y, OutputArray magnitude, OutputArray angle, bool angleInDegrees=false, Stream& stream=Stream::Null())
| Parameters: |
- x – Source matrix containing real components ( CV_32FC1 ).
- y – Source matrix containing imaginary components ( CV_32FC1 ).
- magnitude – Destination matrix of float magnitudes ( CV_32FC1 ).
- angle – Destination matrix of angles ( CV_32FC1 ).
- angleInDegrees – Flag for angles that must be evaluated in degrees.
- stream – Stream for the asynchronous version.
|
|---|
cuda::polarToCart
Converts polar coordinates into Cartesian.
-
C++: void cuda::polarToCart(InputArray magnitude, InputArray angle, OutputArray x, OutputArray y, bool angleInDegrees=false, Stream& stream=Stream::Null())
| Parameters: |
- magnitude – Source matrix containing magnitudes ( CV_32FC1 ).
- angle – Source matrix containing angles ( CV_32FC1 ).
- x – Destination matrix of real components ( CV_32FC1 ).
- y – Destination matrix of imaginary components ( CV_32FC1 ).
- angleInDegrees – Flag that indicates angles in degrees.
- stream – Stream for the asynchronous version.
|
|---|